Case Study: Spot by NetApp
Designing a Kubernetes solution for software engineers working in big data and AI.

Company: Spot by NetApp
Role: Lead Product Designer
Timeline: 8 months
Deliverables: UI design, UX research + insights, wireframes, prototype
Tools: Figma, FigJam
Teammates: Product Manager, Front-End Designers, Back-End Designers, Product Designers
Challenge: Building a solution for big data teams to help them operate and manage cloud infrastructure in a scalable and efficient way.
Project Details
Spot by NetApp is a CloudOps company helping software engineers with cloud infrastructure automation and optimization. I joined the Ocean for Apache Spark team to design a cloud native Kubernetes solution for big data and AI.
As the Lead Product Designer I handled this project end-to-end including: user research and user experience design. Of course it is a multi-team effort with collaboration between design, engineering, and product teams.
The Setup
Building, operating and managing cloud infrastructure in a scalable and efficient way remains a challenge for big data teams. Our goal was to build a product that can simplify this for data engineers, developers, and data scientists. Our product leverages Apache Spark, which is the leading analytics tool used for big data and AI and we aim to make Spark infrastructure more developer-friendly.
As we began this project, Spot accelerated our roadmap with the acquisition of Data Mechanics, a fully-managed tool for cloud native Apache Spark. At this point, we had eight awesome new teammates and two existing products to combine.
The Challenge
Our first course of action was to merge the best of both Data Mechanics and Spot’s current solution for Apache Spark. We began with product ideation sessions utilizing FigJam for collaboration to help us identify the most important features from each product. This would help us create the first release of Ocean for Apache Spark. Our entire team gathered, with representatives from product, front-end engineering, back-end engineering, and design to discuss and decide on the direction for the product. After multiple ideation workshops and evaluations of our product use cases, we determined what we wanted to keep from each product and I created a sitemap that represented our decisions. The next step was for me to design the app and validate it with our current customers.
getting started
A decision matrix in Figjam that helped our team prioritize features and data to include in the product.
The initial Sitemap that represented our design direction
User Research
After we had the first iteration of Ocean for Spark designed, I wanted to make sure we were meeting our user’s needs from our platform. We set up validation research sessions with five of our current customers. The goal of the research was to validate our first release product decisions, identify and confirm user’s needs and to further understand each customer’s use cases.
Research Goals

Research Methods
We conducted five remote interview sessions via Zoom and utilized our Figma prototype for testing. We asked open-ended questions and aimed to get quantitative results by asking each user to rate each section of the application: “Would this make your job easier or harder on a scale of 1-5?”

Research Results
All customers were enthusiastic about having visibility into their cloud cost. This is generally hidden among cloud providers and we are surfacing it front and center for them. Our biggest area of improvement was Configuration Templates.
Based on user feedback, we added search and filtering functionality to improve discoverability and management of configurations. While conducting our research we found that our cluster section performed well. (see below)

The Design
“Generally I care more about what’s going WRONG than of what’s going well.” - user interview
As we continued to iterate on the UX design of our application, we leveraged this user research quote as a guidepost and focused on improving the data visualizations that would help Data Engineers debug inefficient workloads. The first release of the product was the result of an iterative, collaborative, and user-focused design process.
Our team started our process with two products. We combined the best of them both and improved the product along the way. Here you can see the first iteration of the Spot product, the Data Mechanics product, and finally the improved version of them both - Ocean for Apache Spark.
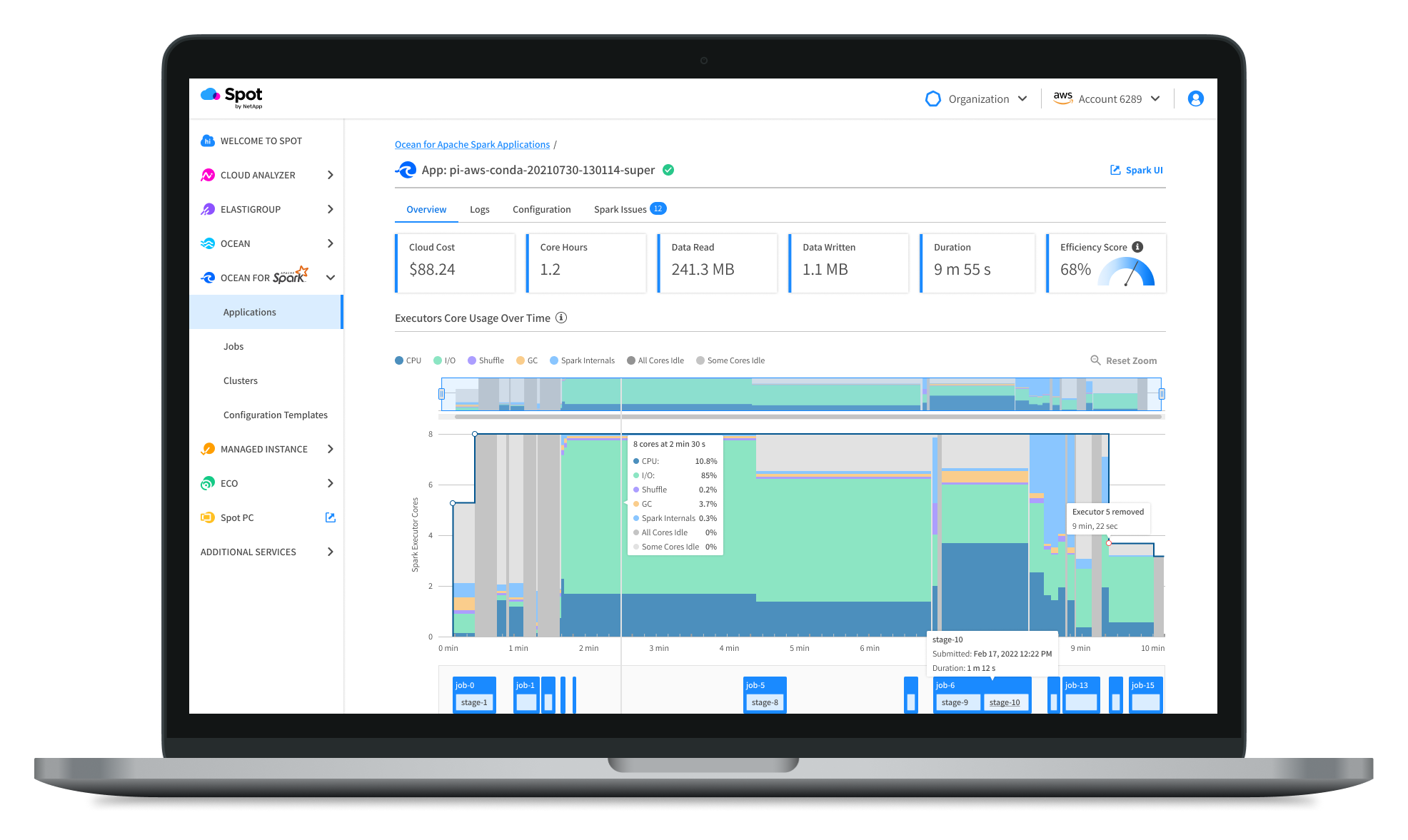
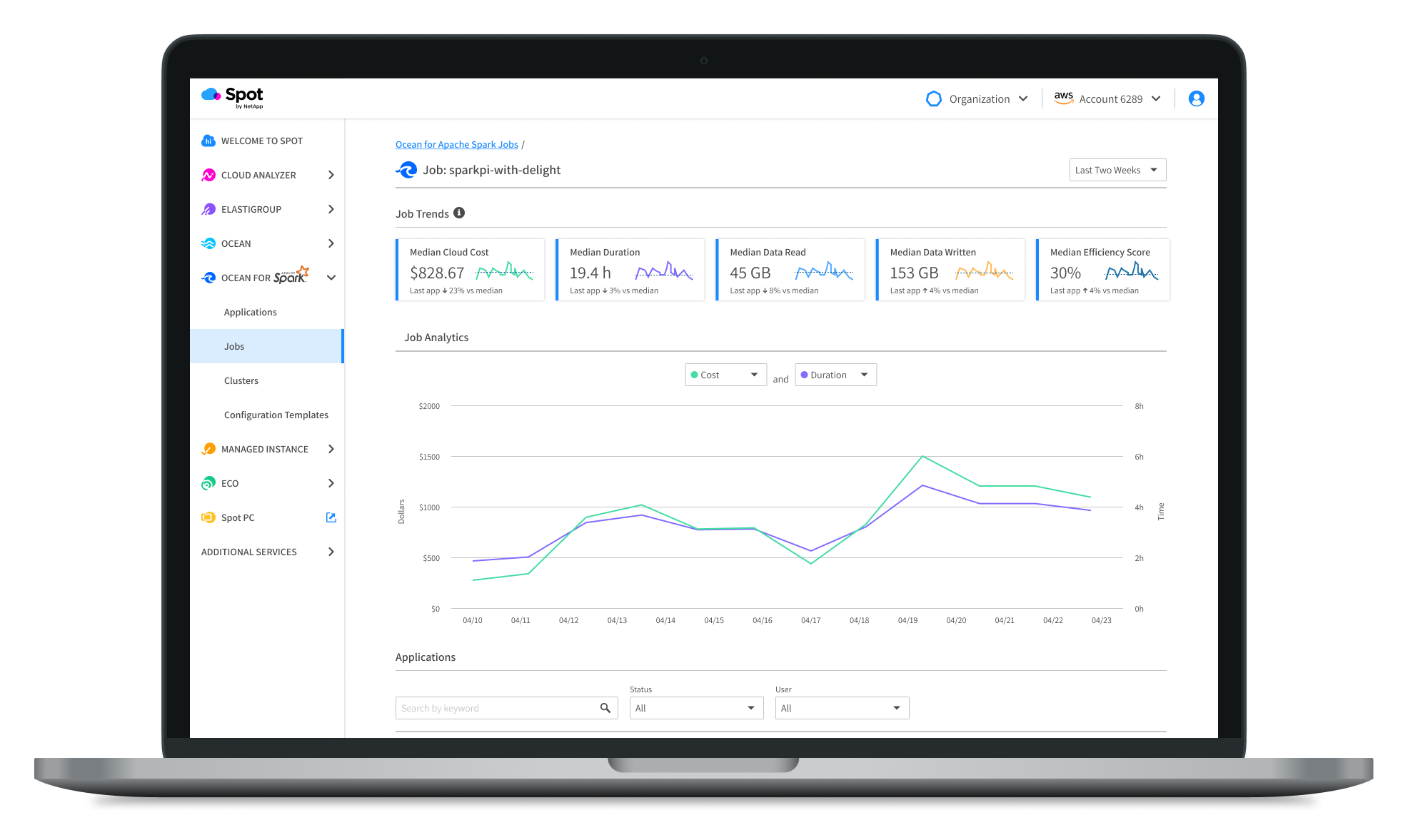
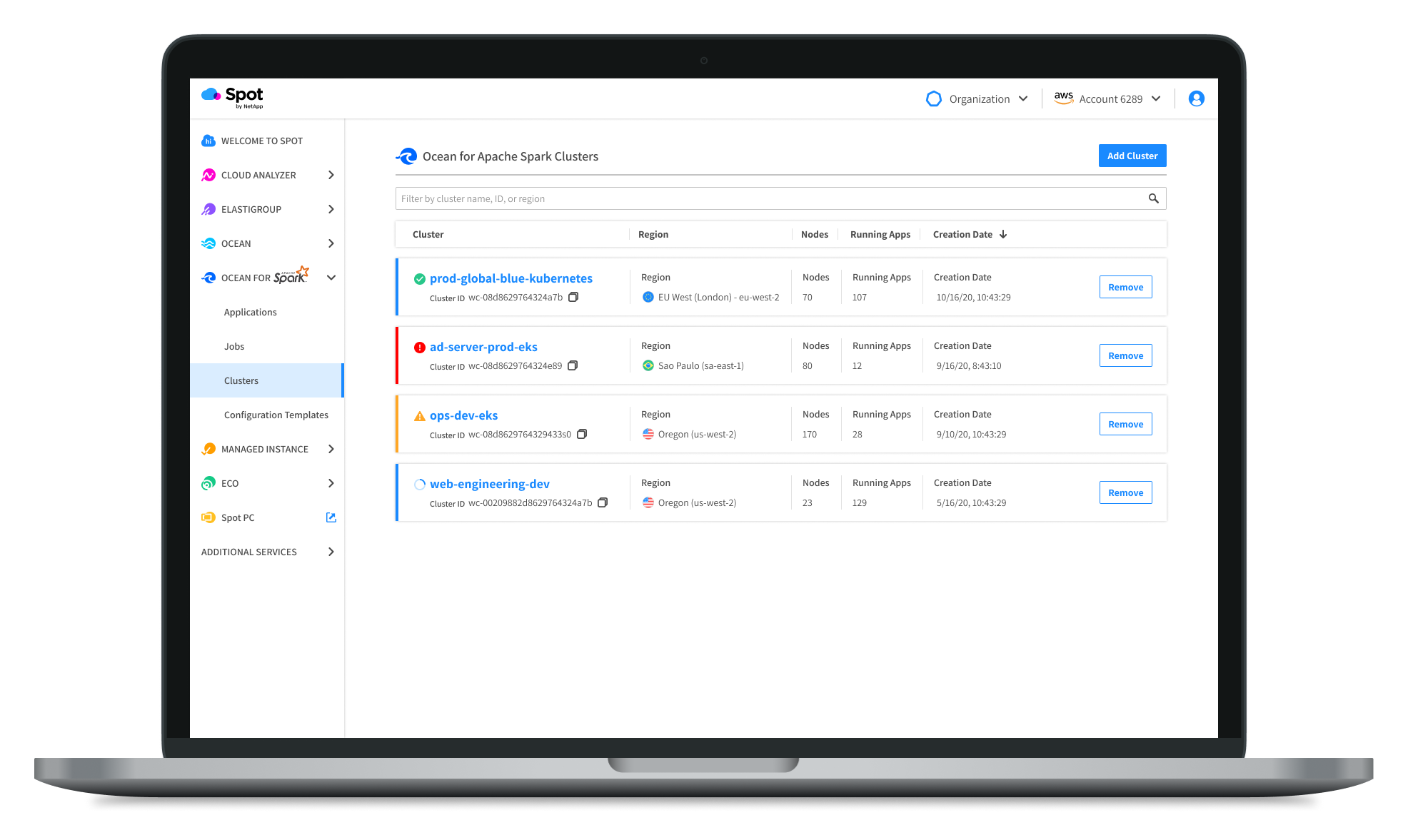
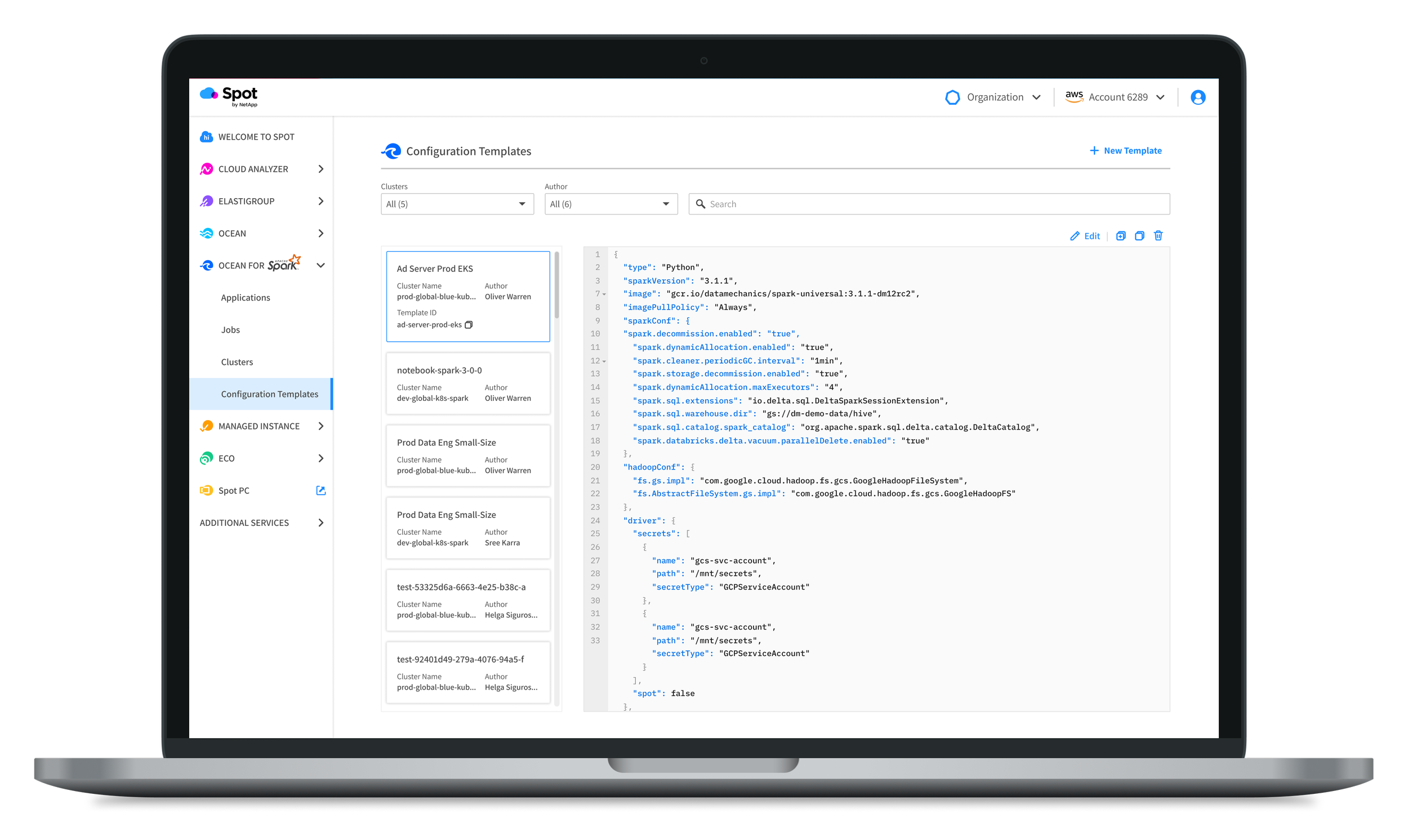
Moving Forward
As the app is released and we onboard our first customers, we will continue to do user research and build out new features for Ocean for Apache Spark. We are also utilizing Fullstory, an analytics tool, to help us understand how our initial group of users are interacting with our product. The landscape for big data and AI engineering teams is growing quickly and we will push forward to be a leader in this space.